

今年的EDA/IP与IC设计论坛上,我们看到了更多AI带来的影响…
发布时间:2026-04-06 发布方:雷娜科技拓驰猎头创始人杨徽来在最近Aspencore主办的IIC Shanghai 2025同期论坛EDA/IP与IC设计论坛上说,整个半导体行业,尤其是芯片设计行业,犹如一场马拉松:体现在高难度、长流程,“职业生涯规划的进阶没有那么快。”这可能是芯片与电子系统设计领域的现状。
但另一方面,他也说行业技术近两年变化极大,AI技术的发展令GPU, NPU, LPU等成为新热点;AI不仅为半导体行业带来了新的机遇,同时也在赋能电子系统设计。我们也从本场EDA/IP与IC设计论坛看到,在AI技术的推动下,该领域内的4个重要趋势:AI辅助芯片与系统设计、异构集成/先进封装令设计难度陡增、国产IP与EDA工具走向创新、RISC-V愈发成为行业内的香饽饽。

Agentic AI:已经在赋能芯片设计
从以ChatGPT为代表的生成式AI爆发,到有思考能力的agentic AI(代理式AI或智能体AI)流行,至现如今的龙虾上桌,AI智能水平的极速上升及使用成本的疯狂下降就在这短短1、2年间。去年Cadence还在活动上展望生成式AI、agentic AI于芯片设计的价值,到现在agentic AI就已经在芯片设计领域逐步落地。
Cadence中国区及东南亚产品技术总监倪乐在主题演讲中说,现如今大部分高阶芯片设计,都有AI辅助工具的参与,“拐点已经来了”。他以验证为例,谈到了Cadence如何将agentic AI融入到EDA工具之中,提升验证的效率:“如果验证过程能够由执行不同任务的agent完成,你只需要输入提示词就行,这会不会是个很大的改变?”
借助Cadence去年收购获得ChipStack AI平台,以及与Cadence EDA工具的深度整合,倪乐在论坛上介绍了“世界上首个AI芯片验证虚拟工程师,它可以将80%的验证工作量,在分钟级内完成”。其工作流程包括读入spec和RTL,在理解设计之后,制定验证计划、写测试代码、与EDA工具集成,去运行、修复和debug测试,“最终给出验证过的design”。在此过程中,“工程师作为领航员,AI作为Copilot,提升了工作效率。”
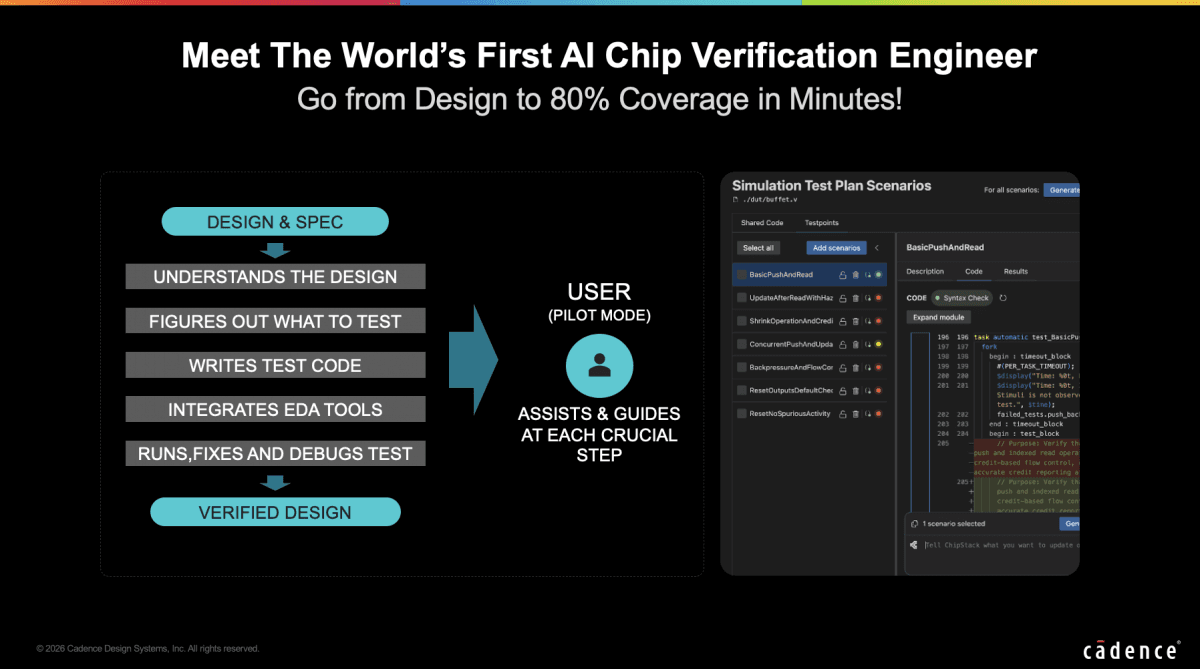
如上图所示,Cadence称其为“端到端的AI辅助验证”。在设计理解(design understanding)环节,AI读入spec和RTL;随后“ChipStack会抽取设计信息,抽象为Mental Model心智模型”;随后的迭代验证(iterative verification),则由AI制定测试计划、产生testbench与验证环境,据此借助EDA工具去跑测试用例,“发现问题再进行迭代”。
以上方法用到了多个agent,包括心智模型agent、形式验证agent、单元测试agent、UVM agent。还真是将agentic AI用到了严肃生产场景中,且是个高度复杂场景。倪乐表示在客户的实际案例中,以上方法能够提升超过70%的验证效率,虽然他也提到现阶段还不推荐客户把subsystem或整个芯片都推给这名“虚拟工程师”去验证,而在block level上。
据说某头部客户采用该方案,将原本两周的工作缩短到了4小时。“7分钟内,ChipStack读入设计并产生mental model——发现spec之中少了一个信号;修正完成后,在15分钟时产生test plan,再去产生testbench;然后跑Jasper”;“第40分钟,它发现了设计问题,所以收紧assumption;此后又加了更多端到端的场景测试,发现了一些潜在bug;最后阶段,基于自然语言交互完成验证过程,达到PCC 92%,COI 98%的效果”;“客户此时就比较有信心去做tapeout了”。
这些都并不仅停留在概念阶段,倪乐给出的数据是,目前ChipStack在头部客户已经有超过10个部署案例(deployment),涵盖传统的芯片设计公司、超大型云服务提供商、AI芯片团队等。
倪乐还提到,除了验证之外,“整个数字芯片设计流程都可以由AI赋能,从spec到RTL生成,再做形式化验证、数字实现、物理signoff,都可以做”。在agentic工作流之中,将人换成agent,“每个步骤都有对应的实现,并且会有check agent实时监督设计对不对,还有分析agent、修正agent...
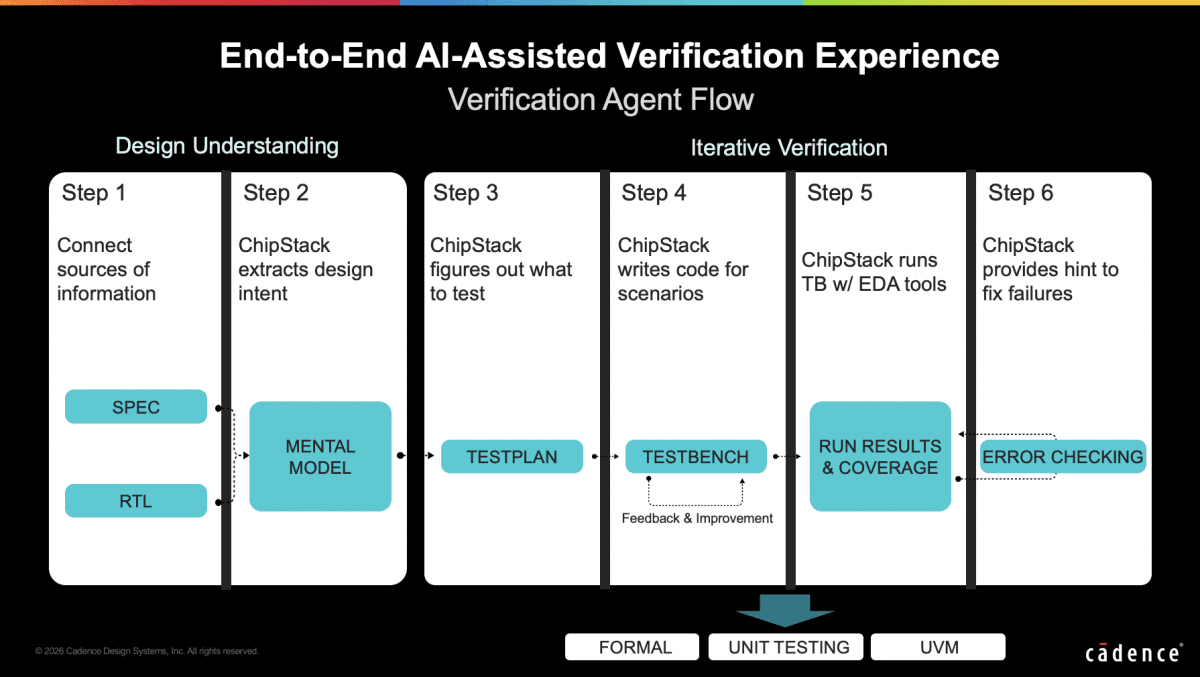
如上图所示,对用户而言,只需要和UI agent对话即可:UI agent分析用户意图,理解究竟是需要将工作转交给design creation agent还是设计实现的agent——这两个agent再将具体的任务分发给不同的agent,具体的agent又会去调用工具完成工作。“整个agent团队来帮你干活。”
比如Cadence的AI辅助数字实现,具体是在Cerebrus AI Studio产品之中:借助不同的agent覆盖从design planning到design closure的所有任务,实现效率的大幅提升。
而在模拟设计方向上,Cadence Virtuoso Agentic AI同样准备就绪,“同样使用不同的agent负责不同的事情”。包括不同工艺的迁移、针对复杂文档与资料的问答、基于复杂逻辑推理的SKILL代码生成...以及在形成“超级智能体”之后,串联工作流——“工程师只需要做监督、检查、引导就行”。
未来走向更高级的智能(Cadence定义为Level 5 Autonomy自主设计),基于提示词和IP、spec、工艺等相关需求,“AI就能自动调用各种各样的RTL生成工具、生成IP、连接现成的IP、完成SoC集成、完成验证、完成物理实现,交付...”加上Cadence近两年还将视野放远到电子系统+物理系统,其agentic AI助力设计的目标大约还会更加长远。
对Candece的AI辅助电子系统设计、5个智能等级、系统级数字孪生解决方案发展策略感兴趣的读者,可点击这里查看电子工程专辑去年的报道。
先进封装碰上EDA:工具链、设计范式要变
将目光从AI赋能电子系统设计,转向AI芯片设计对整个行业提出的挑战问题。谈AI芯片就不得不谈先进封装。“后摩尔时代”一词的关键就是先进封装,或者更进一步可以收窄到2.5D/3D先进封装。因为支撑前道器件微缩的摩尔定律无以为继之时,算力和效率持续提升的关键组成部分之一,就是异构集成、chiplet、先进封装。
2.5D/3D先进封装的本质,就是将die/chiplet以横向或纵向的方式做同封装内的堆叠。珠海硅芯科技有限公司创始人兼CEO赵毅在演讲中说,“由于AI的推动,现在我们能看到最多的可能是逻辑+HBM die的堆叠;未来还会有各种形式的堆叠,比如模拟+数字+射频...”
他举例提到业界前不久“很火的一颗3.5D芯片,整个SoC拆成了compute die, IO die, memory die;且三颗die垂直堆叠。虽然看起来就3层,但从设计、仿真、测试流程来看,需要解决的问题非常之多。”“在堆叠场景发生变化的情况下,于设计工具链而言也提出了新需求。”
总的来说,“当先进封装碰上EDA,整套EDA工具链、design flow都会发生重大改变;且在全新工具链之外,“一定要加上先进封装各种类型工艺的深度协同,并考虑堆叠的具体场景”。即简单来说,工具链要变,设计范式也要变。这对EDA市场参与者而言就构成了挑战。
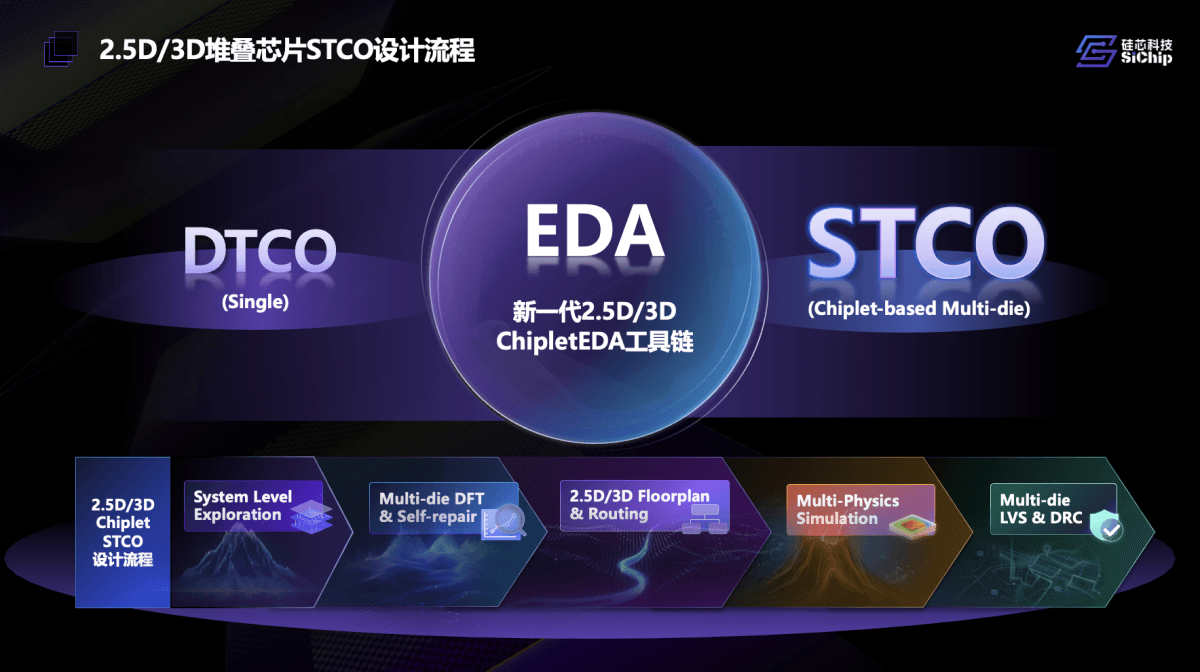
设计流程上发生的转变,是从单芯片的DTCO走向了多芯片的STCO(system-technology co-optimization)。首先是顶层架构探索规划:每片die的类型、架构、工艺选择(连的是什么);每片die的摆放规划、如何连接、IO分布等(可以怎么连);以及“die连接后的性能预分析问题”(怎么连得好)...“做单die设计时我们原本熟悉的4个环节需要全部重构”。
到具体实现的布局布线,呈现的几大难点被赵毅归结为“CIS”(Chiplet, Interposer, Substrate):首先是对于每颗chiplet,核心模块、IO分布,die-to-die物理设计工具、约束等;涉及基于interposer的互联时的电源网络与信号布线,“要全部重做”;以及substrate基板层的RDL与跨层协同设计。
他还特别举例提及,诸如hybrid bonding混合键合技术能够实现显著更高的键和密度,“但没有EDA工具的支持,根本无法达到这样的布线密度”,所以“工艺要与算法深度绑定”。“从2.5D/3D布局布线角度看,所有算法都需要重做;面对不同的场景可能还需要做针对性适配”。
最终,chiplet、silicon interposer(硅中介)、package substrate(封装基板)的“跨层级协同优化”是赵毅在演讲中反复强调的关键。而当涉及垂直堆叠的3D IC设计时,相比2.5D更需要面对“解空间爆发性增长”的挑战...
有关仿真,多物理场协同是不少EDA企业都意识到的挑战;另外相关跨工艺(不同类型的chiplet)、跨层级(CIS);以及设计仿真协同——“如果不做真正的设计仿真协同,一定会面临非常多的回调;甚至可能因为堆叠复杂度变高,面临设计无法收敛的问题”。
针对设计仿真协同的问题,他还举例提到了翘曲(warpage):设计复杂度变高以后,“解决thermal induced可靠性问题一定要做两件事:一是将可靠性前置,在做顶层架构设计规划时,就分析thermal profile、current density、power density...通过前期仿真,就从设计角度做规避——所谓的可靠性就是设计出来的;二是针对生命周期的可靠性问题,加上片上测试与修复、冗余。”
有关验证,“多die的LVS, DRC与单die又不一样。横向与纵向互联时,有其特殊的设计规则”;
有关测试,“测试是刚需”,面临的挑战包括需要新的缺陷机制和失效模型,对应的多die新型DFT电路设计,到新标准的诞生——“IEEE因此做了3D IC DFT的1838标准——这是我们当时和我的导师一起做的,我们从2010年就开始研究了”;以及“需要有自修复机制”等等...以上这些就是STCO的大致流程,“当然DFT需要前置”。
赵毅表示,硅芯对“所有的点工具都做了重构;我们的设计范式也走向了PPPAC,将package作为深度思考的一部分,加入到设计理念中来”,“做完架构,要把DFT,包括冗余、自修复的机制加进来,还要做die-to-die的布局布线、同时做仿真协同,最后做多die LVS......所有这些都要加个multi-die,因为它从工具到算法都与单die差别很大”。

硅芯的设计平台名为3Sheng Integration,“我们的整个工具链平台可以做CIS多层级的协同设计,并关注性能、成本、可测试性的协同优化。”据说客户落地案例已经涵盖了同构堆叠、逻辑+存储、模拟+数字+射频、硅光EIC+PIC,“甚至超大规模堆叠”。
总的来说,硅芯引入的“EDA+”新范式是指,“新一代基于chiplet的EDA工具链+先进封装制造工艺+不同的异构异质集成堆叠芯片场景”协同,“在EDA+新范式下,实现产业链上下游的共同合作。”
国产EDA、IP正走上创新之路
赵毅在演讲中提到,先进封装致电子系统设计复杂度提升的这种转变,也会给中国半导体行业带来机会,需要“工艺、EDA、design house,甚至先进封装设备厂等角色之间的合作”。即便不谈基于2.5D/3D先进封装的复杂电子系统设计,近两年的EDA/IP与IC设计论坛上出现了更多中国企业的身影——硅芯科技本身就是代表企业之一。
本届论坛上,在国产EDA领域同样颇具代表性的还有巨霖科技。巨霖科技技术支持部总监董佳龙分享的主题是高速接口SI signoff仿真对SPICE的挑战。他除了谈到SPICE的发展历程——包括从最初UC Berkeley上世纪70年代明确SPICE思路及以高精度仿真电路的True-SPICE,到90年代略牺牲精度大幅提高仿真速度的FastSPICE,以及后续StatEye统计算法的引入实现快速求解;
还介绍了巨霖科技的SI signoff工具,作为True-SPICE的PanosSPICE——“包含业界主流的device model,涵盖我们和东南大学联合开发的GaN与SiC的部分工艺模型”,“同时在精度方面得到客户认证,能够在模拟混合式信号集成电路设计与IP验证等领域,提供golden级别的精度”;
以及搭载瞬态仿真与StatEye仿真功能的一站式仿真平台SIDesigner,“涵盖业界主流的SI/PI仿真工具的所有基本功能”,“在精度和稳定性方面也能提供与业界golden对标的水准”,“与客户合作了诸如DOE, RSFEC等增值功能”...
不过更重要的是,他谈到巨霖科技对于SI signoff面临挑战的思考:即现如今StatEye也面临高速接口SI signoff仿真的挑战。“以DDR为例,仿真流程可以分成带jitter进行仿真,和不带jitter直接对channel进行仿真。”对于后者,“不同厂商很可能用同一颗SoC连接不同DRAM,SoC的行为必然是不一样的。文档给出SoC的jitter参考值通常是一样的。”“但文档给到的jitter值过于悲观(保守),仿真过不了的,实测有时可以过。”
而“如果带jitter进行仿真,那只能通过bit by bit或统计域仿真两种方式进行。”基于逐bit仿真流程会遭遇的问题包括:“以Rj为例,起码需要数百万、千万个点才能较好地表征高斯分布——也就需要仿真百万千万bit才能够较好地对Rj进行建模——如此一来仿真时间是无法接受的。”
“如果少仿一点,只能通过外插的方式去得到误码率——外插算法精度本身存疑,比如Dual-Dirac模型比较简单,也不适用所有场景。所以通过外插的方式得到超低BER码率的方式也存在问题。”
董佳龙表示,“如果不用bit-by-bit,用最标准的统计域算法,其问题在于StatEye统计算法建立在线性时不变的假设基础之上——当StatEye算法用在像DDR这样的接口上,非线性和串扰等影响变得不可忽视,线性时不变的假设不再成立,算法的精度问题就体现出来了。”
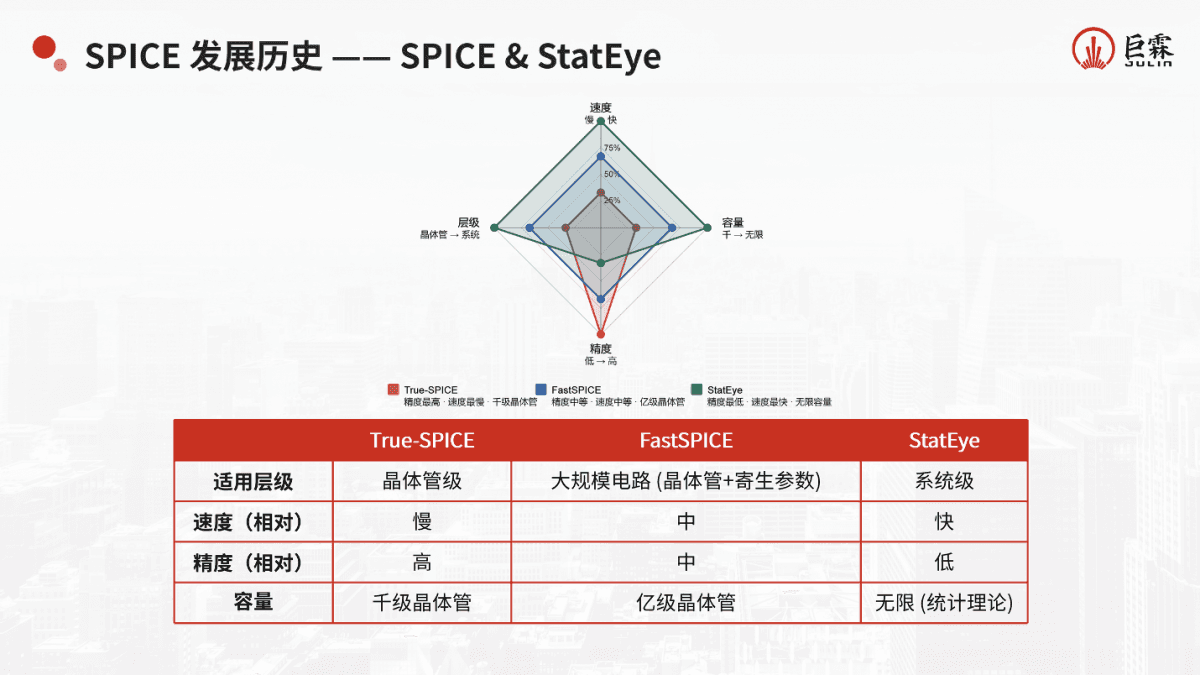
于是对于DDR而言,“业界没有公认的绝对的signoff流程,各厂商都有自己的方案。”有工程经验的大厂或许能解决问题,“但对中小企业而言,没有历史可靠数据做参考,就做不到。

“这些问题体现在SPICE端”,如上图所示。董佳龙介绍说,“目前SPICE有两种算法:Channel Sim算法和经典的全瞬态算法。”前者效率高、灵活性强,但因为线性时不变假设导致存在精度问题;后者没有精度问题,但仿真速度慢,“要得到超低BER值,花费的时间无法接受”,且“面对jitter, BER等需求时,低效笨拙”。
董佳龙提到,巨霖对于上述挑战有两个方向的思路:尝试在瞬态仿真中加入bit by bit的部分feature,“替代原本bit by bit的生态位,精度更高”;
或者针对统计域算法,可以考虑“妥协StatEye的速度,换取精度上的大幅提升。”——“比如StatEye流程上是利用阶跃响应去做统计域算法,得到误码率的值;那么我们能否在瞬态仿真阶跃响应的阶段做更多的事情,让它更好地表征整个系统的非线性或串扰这些之前没有考虑到的东西,然后再去对整个电路应用统计与计算,得到误码率值。”
“如此一来,精度更高,只不过花费的时间可能会更久。”“如果能够解决精度问题,就像FastSPICE用速度换精度那样,用可接受的速度换取更高的精度或许也有机会在生态位中占据一席之地。”在我们看来,这番思考已经能够表现国产EDA企业走在创新之路上了——故而今年巨霖科技同样得到了中国IC设计成就奖年度技术突破EDA公司奖项。

EDA之外,从国产IP的角度来看,另外一家EDA/IP与IC设计论坛的常客灿芯半导体(上海)股份有限公司在今年的中国IC设计成就奖之上获得了“年度创新IP公司”奖项。这与灿芯推向市场的IP产品是分不开的,也代表了中国电子系统设计发展的高水平。灿芯半导体(上海)股份有限公司项目总监孙翔特别谈到,就模拟IP市场发展趋势,竞争格局正表现出“本土崛起”,和各家的“差异化突围”。
对于模拟IP发展的市场驱动力,他谈到AI技术的高速发展及最终落地也离不开模拟芯片,“高算力芯片需要可靠的电源供电,AI落地还需要对物理世界做感知”;AI也因此能够推动模拟芯片市场的发展,涵盖诸多垂直领域——“模拟IP最大增量市场是车规产品,最广泛应用为边缘计算,最稳健的是工业、通讯、医疗”。
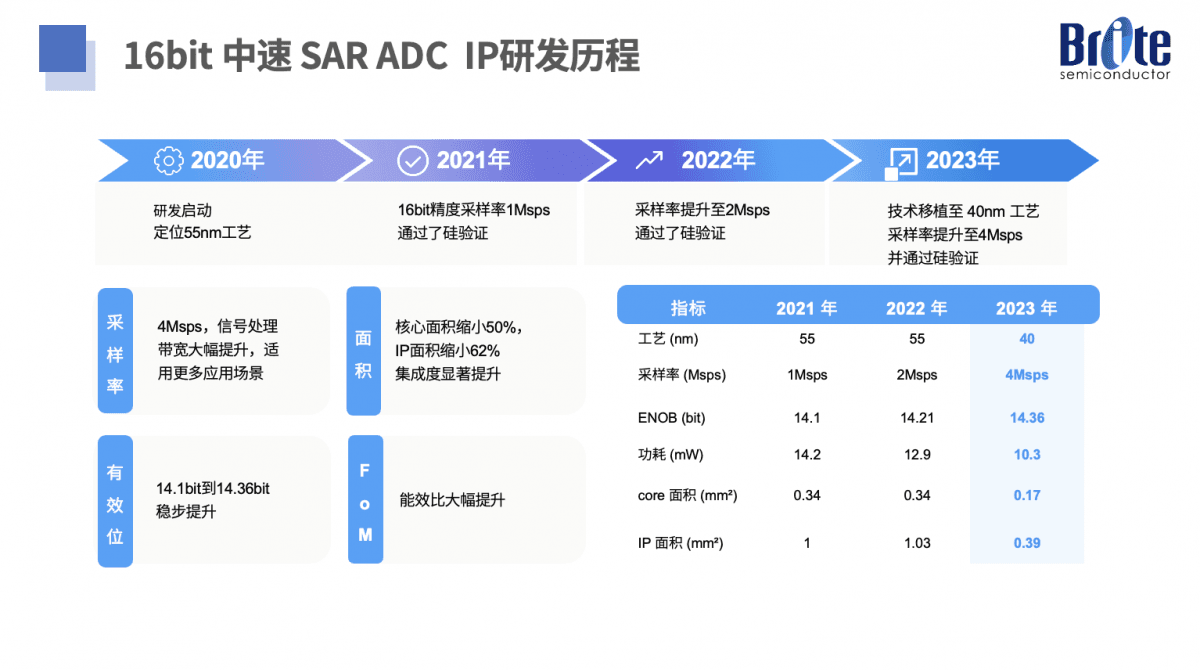
上面这张图表现了“灿芯半导体在模拟IP领域的技术积累”,孙翔在演讲中介绍了灿芯自2020年起开始研发16bit中速SAR ADC的历程。包括2021年55nm 16bit 1Msps的ADC通过硅验证;2022年将采样率提升至2Msps;2023年为满足市场需求将工艺迁往40nm,采样率也提升至4Msps——与此同时核心面积缩小50%,IP面积缩小62%,能效比大幅提升...
这款16bit中速ADC IP面向工业测控、汽车电子、仪器仪表、医疗电子等市场。除了表现出出色的性能与效率指标,关键技术还包括噪声增强技术(额外的SAR周期)、粗量化+精细量化(降低信号电压,划分电源域,提升速率)、桥接电容结构(容忍参考误差)、差分模式共模范围检测(共模范围预警),以及灿芯的专利技术DAC切换开关(单端/差分输入模型灵活切换)和自校准功能(非理想电容、失配、增益误差补偿)...
与此同时,孙翔还给出了这款16bit中速ADC IP在SoC应用环境中的不同性能表征:“基于我们的大量客户案例和经验,我们会向客户提供丰富的应用说明,来告知客户如何在其SoC芯片中,将ADC的性能完全发挥出来。”“我们也发现,封装的集成电容和电感会对ADC性能产生影响,我们对其性能表征都有深刻的认识。”所以,“灿芯在IP到芯片应用环节,以及后续封装,都能够给客户以经验指导”,“当然我们也会提供SI/PI仿真服务、技术支持”。
受限于篇幅,孙翔介绍的来自灿芯的,包括12bit中速SAR ADC IP、通用高性能PLL IP、通用低功耗PLL IP、专用低抖动PLL IP,以及40nm工艺之上的EF/车规IP等产品和平台,本文不再展开。感兴趣的读者可前往灿芯官网做进一步了解。
RISC-V持续向高性能拓展
从CPU指令集和架构的角度,AI时代最热的话题之一,无疑就是RISC-V。此前电子工程专辑多番撰文谈过为什么说RISC-V指令集与AI应用格外适配:开放性、灵活性,以及逐渐健全的生态是其最大助益。RISC-V从嵌入式应用走向HPC也因此成为探讨该指令集生态的热门话题。
赛昉科技销售副总裁周杰概括RISC-V在HPC高性能计算之中的发展趋势包括(1)多核与众核扩展;(2)异构集成协同——混合架构SoC是HPC与AI芯片的常见形态;(3)新兴技术融合——主要是指生成式AI的发展,令芯片内的数据带宽需求越来越高。
所以周杰在主题演讲中介绍的是赛昉的一致性片上网络NoC IP StarNoC。NoC对于高性能处理器的价值无疑是巨大的,是多核系统的基础设施。“如何提供高性能、保证可扩展性,以及底层异构架构对上层透明等,NoC至关重要。”借助RISC-V领域NoC IP的发展,32核、40核、64核RISC-V CPU也变得常见。
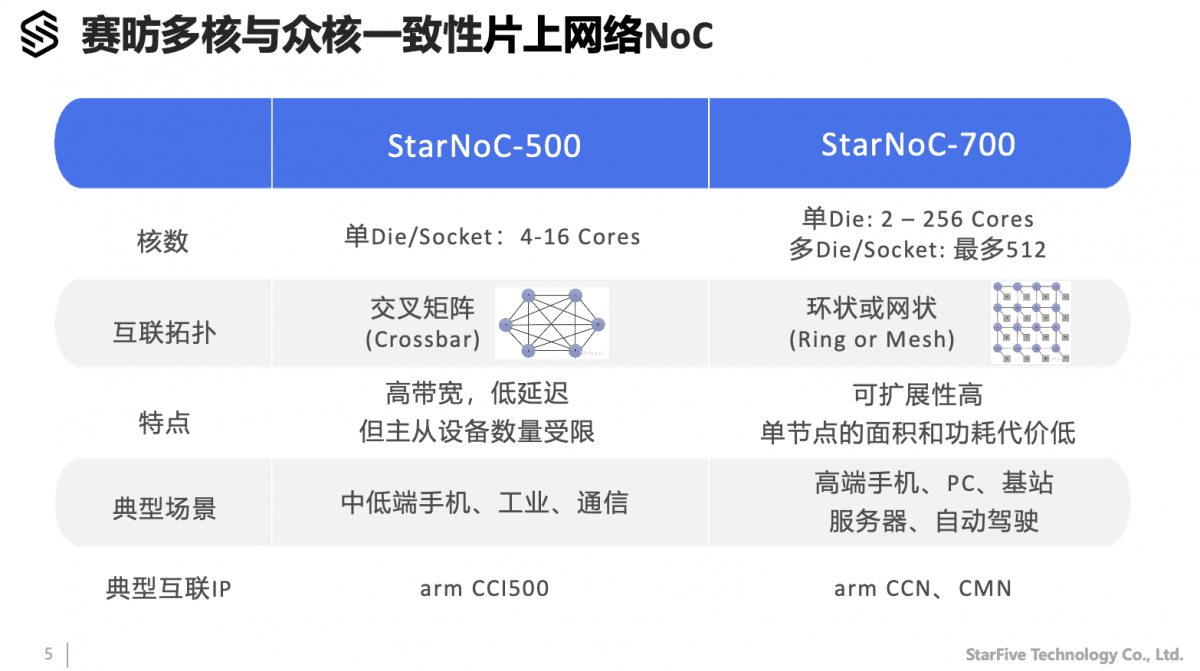
上面这张图展示了赛昉科技的StarNoC-500和StarNoC-700。前者采用crossbar交叉矩阵拓扑结构,支持至多16核互连——面向手机、工业与通信应用等领域;后者基于ring或mesh拓扑,最多支持256核,在多die或多socket的情况下可实现512核扩展——面向PC、基站、服务器、自动驾驶等应用方向。
StarNoC-500支持最多4个FCM(全一致性master)端口,通过CAL接口扩展最大16个核心;支持至多3个一致性IO端口。周杰介绍说,赛昉“已经成功将StarNoC-500,搭配赛昉自研的RISC-V IP(Dubhe-70),应用到JH-B100芯片之上,并成功进入量产”——这是一颗服务器基板的管理芯片,负责服务器的系统安全和远程运维,“国内几家大的服务器生产商都已经导入”,“将成为数据中心领域首颗规模化量产的RISC-V高性能芯片”。
StarNoC-700是对标Arm CMN片上互联总线的设计方案,采用ring/mesh拓扑结构,采用CHI.E协议;分布式CCU节点,包含snoop filer & SLC;其他重要特性和构成还包括,单节点支持东西南北6向连接,可配置不同连接属性——如全一致性CPU节点、memory节点等;“针对IO提供两种不同支持方式:支持PCIe的slave节点,也可以支持GPU这类master的节点,以及其他一些小节点...”
这款IP藉由mesh的双通道设计,在2GHz频率、256bit位宽的情况下,可提供最大128GB/s带宽...其他相关带宽与延迟的性能数据、总线规模、可配置性、核心组件CCU(cache coherency unit)等诸多特性与细节,感兴趣的读者可查阅官方文档。目前StarNoC-700“已经进入客户交付阶段”。
“我们自己也将StarNoC-700与RISC-V核做了适配,进行了实践”,包括2x2 Mesh NoC(1-3核, FPGA单片), 4x4 mesh/4-node ring NoC(8/10核, FPGA四片), 2x3 mesh NoC(SOC芯片硅验证),做不同阶段的验证——最后的硅验证阶段,从PPT来看正在进行中。从赛昉公布的数据来看,多核性能的线性度表现符合预期。
